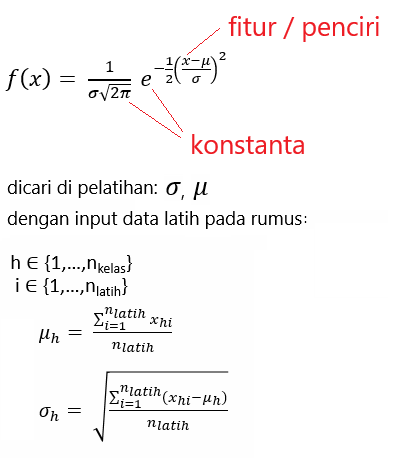
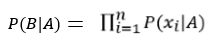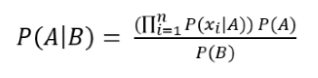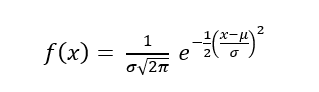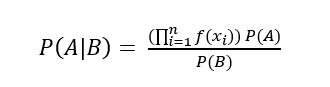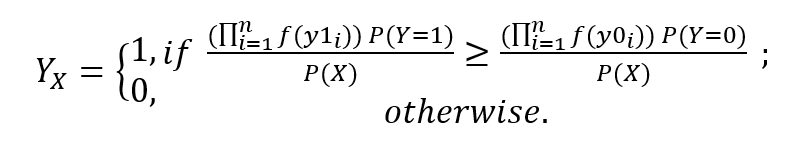Gaussian Naive Bayes adalah jenis metode Naive Bayes yang mempertimbangkan atribut kontinu dan fitur data mengikuti distribusi Gaussian di seluruh kumpulan data. Sedangkan Naive Bayes sendiri didasarkan pada konsep sederhana dari teori probabilitas yang disebut Teorema Bayes. Algoritme klasifikasi ini bekerja dengan sangat baik dalam memprediksi kelas yang tepat dari fitur-fitur yang ada.
Daftar Isi
Penerapan Gaussian Naive Bayes Gaussian Naive Bayes adalah jenis algoritma klasifikasi yang bekerja pada fitur terdistribusi normal kontinu yang didasarkan pada algoritma Naive Bayes. Data numerik maupun non-numerik dapat diselesaikan dengan GNB.
— Gaussian Naive Bayes https://bptsi.unisayogya.ac.id/gaussian-naive-bayes/ 2024-04-15 12:03:04
Bayes Naive Naive Bayes Gaussian Gaussian Naive Bayes Training Gaussian Naive Bayes Klasifikasi Gaussian Naive Bayes Gaussian Naive Bayes Pada Data Numerik Data GNB Numerik Var 1 Var 2 Klasifikasi x1 0.1 0.2 kelasA x2 0.5 0.9 kelasB x3 0.4 0.3 kelasA x4 0.6 0.8 kelasB
data latih Var 1 Var 2 Klasifikasi x5 0.3 0.2 kelasA x6 0.6 0.9 kelasB x7 0.5 0.4 kelasA
data uji Penyelesaian Dengan Program GNB Numerik import numpy as np
# Data latih
v01X_train = np.array([[0.1, 0.2], [0.5, 0.9], [0.3, 0.3], [0.7, 0.75]])
v02y_train = np.array(['kelasA', 'kelasB', 'kelasA', 'kelasB'])
# Memisahkan data latih berdasarkan kelas
v03X_kelasA = v01X_train[v02y_train == 'kelasA']
v04X_kelasB = v01X_train[v02y_train == 'kelasB']
# Menghitung probabilitas prior
v05prior_kelasA = len(v03X_kelasA) / len(v01X_train)
v06prior_kelasB = len(v04X_kelasB) / len(v01X_train)
# Menghitung mean dan varians untuk setiap fitur dan kelas
v07mean_kelasA = np.mean(v03X_kelasA, axis=0)
v08var_kelasA = np.var(v03X_kelasA, axis=0)
v09mean_kelasB = np.mean(v04X_kelasB, axis=0)
v10var_kelasB = np.var(v04X_kelasB, axis=0)
# Menghitung likelihood untuk setiap data uji
def gaussian_likelihood(x, mean, var):
return (1 / np.sqrt(2 * np.pi * var)) * np.exp(-(x - mean)**2 / (2 * var))
# Data uji
v11X_test = np.array([[0.3, 0.2], [0.6, 0.9], [0.5, 0.4]])
v12y_test = np.array(['kelasA', 'kelasB', 'kelasA'])
kelas_prediksi = []
for X_test_ in v11X_test:
likelihood_kelasA = gaussian_likelihood(X_test_, v07mean_kelasA, v08var_kelasA).prod()
likelihood_kelasB = gaussian_likelihood(X_test_, v09mean_kelasB, v10var_kelasB).prod()
# Menghitung probabilitas posterior
posterior_kelasA = likelihood_kelasA * v05prior_kelasA
posterior_kelasB = likelihood_kelasB * v06prior_kelasB
# Mengklasifikasikan data uji
kelas = 'kelasA' if posterior_kelasA > posterior_kelasB else 'kelasB'
kelas_prediksi.append(kelas)
print(f"Kelas prediksi untuk data uji {v11X_test}: {kelas_prediksi}")
from sklearn.naive_bayes import GaussianNB
model_ = GaussianNB()
model_.fit(v01X_train, v02y_train)
# predict output
v13y_test = model_.predict(v11X_test)
print(f"Kelas prediksi untuk data uji {v11X_test}: {v13y_test}")#hasil run
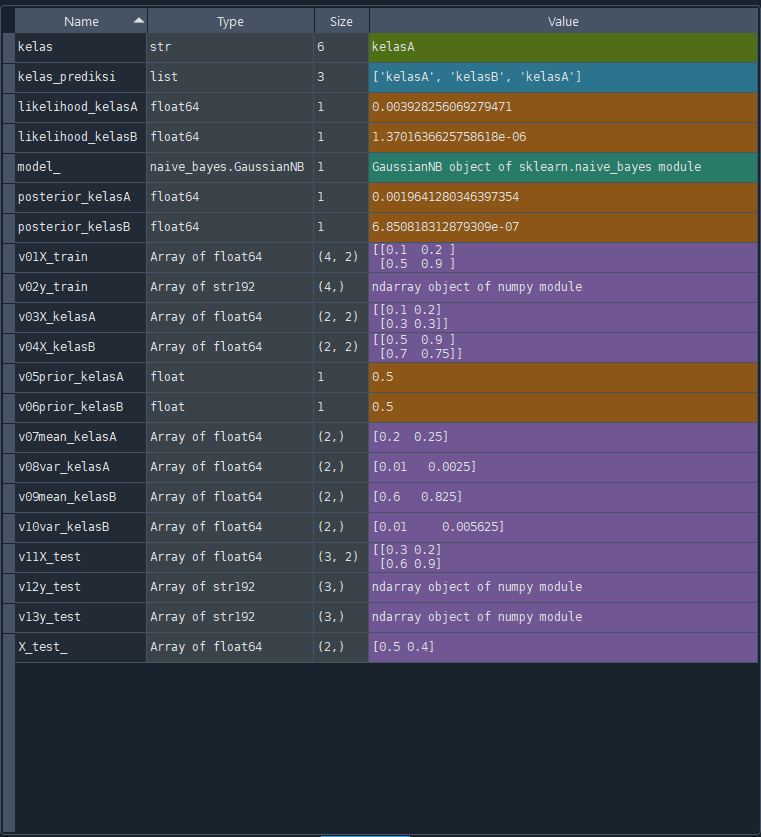
Kelas prediksi untuk data uji [[0.3 0.2]
[0.6 0.9]
[0.5 0.4]]: ['kelasA', 'kelasB', 'kelasA']
Kelas prediksi untuk data uji [[0.3 0.2]
[0.6 0.9]
[0.5 0.4]]: ['kelasA', 'kelasB', 'kelasA']Variabel Terakhir GNB Numerik Penyelesaian Manual GNB Numerik #memisahkan data latih berdasarkan kelas
kelasA = [[0.1 0.2] [0.3 0.3]]
priorA = row(kelasA) / row(latih)
= 2 / 4
= 0.5
meanA = [(0.1+0.3)/2 (0.2+0.3)/2]
= [0.2 0.25]
varA[0]= 1/row(kelasA) * ((kelasA[0][0]-meanA[0])^2+(kelasA[0][1]-meanA[0])^2)
= 1/2 * ((0.1-0.2)^2+(0.3-0.2)^2)
= 0.01
varA[1]= 1/row(kelasA)* ((kelasA[1][0]-meanA[1])^2+(kelasA[1][1]-meanA[1])^2)
= 1/2 * ((0.2-0.25)^2+(0.3-0.25)^2)
= 0.0025
kelasB = [[0.5 0.9] [0.7 0.75]]
priorB = row(kelasB) / row(latih)
= 2 / 4
= 0.5
meanB = [(0.5+0.7)/2 (0.9+0.75)/2]
= [0.6 0.825]
varB[0]= 1/row(kelasB) * ((kelasB[0][0]-meanB[0])^2+(kelasB[0][1]-meanB[0])^2)
= 1/2 * ((0.5-0.6)^2+(0.7-0.6)^2)
= 0.01
varB[1]= 1/row(kelasB) * ((kelasB[1][0]-meanB[1])^2+(kelasB[1][1]-meanB[1])^2)
= 1/2 * ((0.9-0.825)^2+(0.75-0.825)^2)
= 0.005625
#likehood (Gaussian) x7 [0.5 0.4]
#gaussian var 1 * gaussian var 2 * ... * gaussian var n
#likehood kelasA dari x7
Gau[0] = (1/sqrt(2*pi*varA[0])) * exp(-(x7[0]-meanA[0])^2 / (2*varA[0]))
= (1/sqrt(2*pi*0.01)) * exp(-(0.5-0.2)^2 / (2*0.01))
= 0.04431848411938
Gau[1] = (1/sqrt(2*pi*varA[1])) * exp(-(x7[1]-meanA[1])^2 / (2*varA[1]))
= (1/sqrt(2*pi*0.0025)) * exp(-(0.4-0.25)^2 / (2*0.0025))
= 0.0886369682387598
GauAx7 = 0.04431848411938 * 0.0886369682387598
= 0.00392825606927947
#likehood kelasB dari x7
Gau[0] = (1/sqrt(2*pi*varB[0])) * exp(-(x7[0]-meanB[0])^2 / (2*varB[0]))
= (1/sqrt(2*pi*0.01)) * exp(-(0.5-0.6)^2 / (2*0.01))
= 2.41970724519143
Gau[1] = (1/sqrt(2*pi*varB[1])) * exp(-(x7[1]-meanB[1])^2 / (2*varB[1]))
= (1/sqrt(2*pi*0.005625)) * exp(-(0.4-0.825)^2 / (2*0.005625))
= 5.66251832860657E-07
GauBx7 = 0.04431848411938 * 0.0886369682387598
= 1.37016366257586E-06
#posterior x7
PosAx7 = GauAx7 * priorA
= 0.00392825606927947 * 0.5
= 0.00196412803463974
PosBx7 = GauBx7 * priorB
= 1.37016366257586E-06 * 0.5
= 6.85081831287931E-07
#memisahkan data latih berdasarkan kelas
kelasA = [[0.1 0.2] [0.3 0.3]]
priorA = row(kelasA) / row(latih)
= 2 / 4
= 0.5
meanA = [(0.1+0.3)/2 (0.2+0.3)/2]
= [0.2 0.25]
varA[0]= 1/row(kelasA) * ((kelasA[0][0]-meanA[0])^2+(kelasA[0][1]-meanA[0])^2)
= 1/2 * ((0.1-0.2)^2+(0.3-0.2)^2)
= 0.01
varA[1]= 1/row(kelasA)* ((kelasA[1][0]-meanA[1])^2+(kelasA[1][1]-meanA[1])^2)
= 1/2 * ((0.2-0.25)^2+(0.3-0.25)^2)
= 0.0025
kelasB = [[0.5 0.9] [0.7 0.75]]
priorB = row(kelasB) / row(latih)
= 2 / 4
= 0.5
meanB = [(0.5+0.7)/2 (0.9+0.75)/2]
= [0.6 0.825]
varB[0]= 1/row(kelasB) * ((kelasB[0][0]-meanB[0])^2+(kelasB[0][1]-meanB[0])^2)
= 1/2 * ((0.5-0.6)^2+(0.7-0.6)^2)
= 0.01
varB[1]= 1/row(kelasB) * ((kelasB[1][0]-meanB[1])^2+(kelasB[1][1]-meanB[1])^2)
= 1/2 * ((0.9-0.825)^2+(0.75-0.825)^2)
= 0.005625
#likehood (Gaussian) x7 [0.5 0.4]
#gaussian var 1 * gaussian var 2 * ... * gaussian var n
#likehood kelasA dari x7
Gau[0] = (1/sqrt(2*pi*varA[0])) * exp(-(x7[0]-meanA[0])^2 / (2*varA[0]))
= (1/sqrt(2*pi*0.01)) * exp(-(0.5-0.2)^2 / (2*0.01))
= 0.04431848411938
Gau[1] = (1/sqrt(2*pi*varA[1])) * exp(-(x7[1]-meanA[1])^2 / (2*varA[1]))
= (1/sqrt(2*pi*0.0025)) * exp(-(0.4-0.25)^2 / (2*0.0025))
= 0.0886369682387598
GauAx7 = 0.04431848411938 * 0.0886369682387598
= 0.00392825606927947
#likehood kelasB dari x7
Gau[0] = (1/sqrt(2*pi*varB[0])) * exp(-(x7[0]-meanB[0])^2 / (2*varB[0]))
= (1/sqrt(2*pi*0.01)) * exp(-(0.5-0.6)^2 / (2*0.01))
= 2.41970724519143
Gau[1] = (1/sqrt(2*pi*varB[1])) * exp(-(x7[1]-meanB[1])^2 / (2*varB[1]))
= (1/sqrt(2*pi*0.005625)) * exp(-(0.4-0.825)^2 / (2*0.005625))
= 5.66251832860657E-07
GauBx7 = 0.04431848411938 * 0.0886369682387598
= 1.37016366257586E-06
#posterior x7
PosAx7 = GauAx7 * priorA
= 0.00392825606927947 * 0.5
= 0.00196412803463974
PosBx7 = GauBx7 * priorB
= 1.37016366257586E-06 * 0.5
= 6.85081831287931E-07
= 0.0000006850818312879
#penentuan kelas
PosAx7 > PosBx7, sehingga x7 diklasifikasikan ke kelasAHasil GNB Numerik Klasifikasi x5 kelasA x6 kelasB x7 kelasA
hasil klasifikasi Bayes Pada Data Non-Numerik Data GNB Non-Numerik Bentuk Warna Volume Klasifikasi x1 Bulat Coklat Besar Ya x2 Lonjong Hijau Besar Tidak x3 Bulat Coklat Sedang Ya x4 Bulat Coklat Kurang Tidak x5 Lonjong Merah tua Sedang Ya x6 Lonjong Coklat Besar Ya x7 Tidak beraturan Hijau Besar Tidak x8 Bulat Coklat Sedang Ya x9 Tidak beraturan Merah tua Sedang Tidak x10 Bulat Coklat Sedang Ya x11 Tidak beraturan Coklat Besar Tidak x12 Bulat Hijau Besar Tidak
data latih Bentuk Warna Volume Klasifikasi x13 Bulat Coklat Besar Ya x14 Bulat Coklat Sedang Ya x15 Bulat Coklat Kurang Tidak
data uji Penyelesaian Dengan Program Non-Numerik #data latih
#x1 =[Bulat Coklat Besar Ya]
#x2 =[Lonjong Hijau Besar Tidak]
#x3 =[Bulat Coklat Sedang Ya]
#x4 =[Bulat Coklat Kurang Tidak]
#x5 =[Lonjong Merah Sedang Ya]
#x6 =[Lonjong Coklat Besar Ya]
#x7 =[Takteratur Hijau Besar Tidak]
#x8 =[Bulat Coklat Sedang Ya]
#x9 =[Takteratur Merah Sedang Tidak]
#x10=[Bulat Coklat Sedang Ya]
#x11=[Takteratur Coklat Besar Tidak]
#x12=[Bulat Hijau Besar Tidak]
#data uji
#x13=[Bulat Coklat Besar Ya]
#x14=[Bulat Coklat Sedang Ya]
#x15=[Bulat Coklat Kurang Tidak]
#x16 =[Lonjong Merah Sedang Ya]
#x17 =[Lonjong Coklat Besar Ya]
import numpy as np
# Data latih
data_latih = np.array([
['Bulat', 'Coklat', 'Besar', 'Ya'],
['Lonjong', 'Hijau', 'Besar', 'Tidak'],
['Bulat', 'Coklat', 'Sedang', 'Ya'],
['Bulat', 'Coklat', 'Kurang', 'Tidak'],
['Lonjong', 'Merah', 'Sedang', 'Ya'],
['Lonjong', 'Coklat', 'Besar', 'Ya'],
['Takteratur', 'Hijau', 'Besar', 'Tidak'],
['Bulat', 'Coklat', 'Sedang', 'Ya'],
['Takteratur', 'Merah', 'Sedang', 'Tidak'],
['Bulat', 'Coklat', 'Sedang', 'Ya'],
['Takteratur', 'Coklat', 'Besar', 'Tidak'],
['Bulat', 'Hijau', 'Besar', 'Tidak']
])
# Hitung prior kelas
prior_kelas = {}
for kelas in np.unique(data_latih[:, -1]):
prior_kelas[kelas] = np.sum(data_latih[:, -1] == kelas) / len(data_latih)
# Hitung likelihood fitur
likelihood_fitur = {}
for kelas in np.unique(data_latih[:, -1]):
likelihood_fitur[kelas] = {}
for idx_fitur in range(data_latih.shape[1] - 1):
nilai_unik = np.unique(data_latih[:, idx_fitur])
for kelas in np.unique(data_latih[:, -1]):
for nilai in nilai_unik:
likelihood_fitur[kelas][nilai] = (
np.sum((data_latih[:, idx_fitur] == nilai) & (data_latih[:, -1] == kelas)) /
np.sum(data_latih[:, -1] == kelas)
)
def datanumerik(data):
X_ = {}
y_ = {}
for idx_baris, baris in enumerate(data):
kelas = baris[len(baris)-1]
X_[idx_baris] = {}
y_[idx_baris] = kelas
for idx_fitur, fitur in enumerate(baris[:-1]):
X_[idx_baris][idx_fitur] = likelihood_fitur[kelas][fitur]
return np.array([list(row_dict.values()) for row_dict in X_.values()]), np.array(list(y_.values()))
# Data latih dalam bentuk numerik
v01X_train, v02y_train = datanumerik(data_latih)
# Memisahkan data latih berdasarkan kelas
v03X_kelasYa = v01X_train[v02y_train == 'Ya']
v04X_kelasTidak = v01X_train[v02y_train == 'Tidak']
# Menghitung probabilitas prior
v05prior_kelasYa = len(v03X_kelasYa) / len(v01X_train)
v06prior_kelasTidak = len(v04X_kelasTidak) / len(v01X_train)
# Menghitung mean dan varians untuk setiap fitur dan kelas
v07mean_kelasYa = np.mean(v03X_kelasYa, axis=0)
v08var_kelasYa = np.var(v03X_kelasYa, axis=0)
v09mean_kelasTidak = np.mean(v04X_kelasTidak, axis=0)
v10var_kelasTidak = np.var(v04X_kelasTidak, axis=0)
# Menghitung likelihood untuk setiap data uji
def gaussian_likelihood(x, mean, var):
return (1 / np.sqrt(2 * np.pi * var)) * np.exp(-(x - mean)**2 / (2 * var))
# Data uji
data_uji = np.array([
['Bulat', 'Coklat', 'Besar', 'Ya'],
['Bulat', 'Coklat', 'Sedang', 'Ya'],
['Bulat', 'Coklat', 'Kurang', 'Tidak'],
['Lonjong', 'Merah', 'Sedang', 'Ya'],
['Lonjong', 'Coklat', 'Besar', 'Ya']
])
# Data latih dalam bentuk numerik
v11X_test, v12y_test = datanumerik(data_uji)
kelas_prediksi = []
for X_test_ in v11X_test:
likelihood_kelasYa = gaussian_likelihood(X_test_, v07mean_kelasYa, v08var_kelasYa).prod()
likelihood_kelasTidak = gaussian_likelihood(X_test_, v09mean_kelasTidak, v10var_kelasTidak).prod()
# Menghitung probabilitas posterior
posterior_kelasYa = likelihood_kelasYa * v05prior_kelasYa
posterior_kelasTidak = likelihood_kelasTidak * v06prior_kelasTidak
# Mengklasifikasikan data uji
kelas = 'Ya' if posterior_kelasYa > posterior_kelasTidak else 'Tidak'
kelas_prediksi.append(kelas)
print(f"Kelas prediksi untuk data uji {v11X_test}: {kelas_prediksi}")
from sklearn.naive_bayes import GaussianNB
model_ = GaussianNB()
model_.fit(v01X_train, v02y_train)
# predict output
v13y_test = model_.predict(v11X_test)
print(f"Kelas prediksi untuk data uji {v11X_test}: {v13y_test}")#hasil run
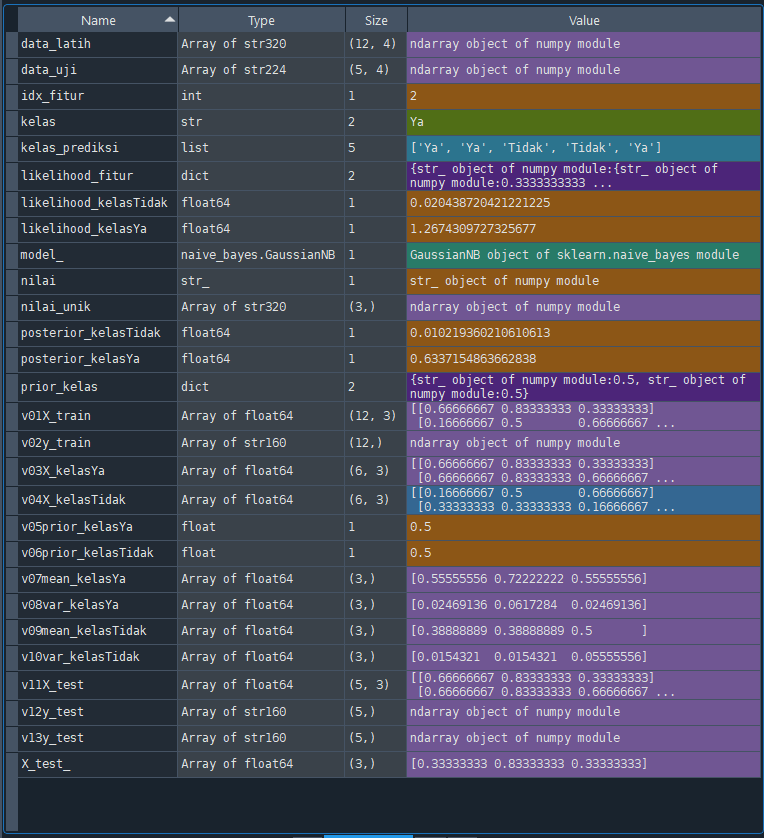
Kelas prediksi untuk data uji [[0.66666667 0.83333333 0.33333333]
[0.66666667 0.83333333 0.66666667]
[0.33333333 0.33333333 0.16666667]
[0.33333333 0.16666667 0.66666667]
[0.33333333 0.83333333 0.33333333]]: ['Ya', 'Ya', 'Tidak', 'Tidak', 'Ya']
Kelas prediksi untuk data uji [[0.66666667 0.83333333 0.33333333]
[0.66666667 0.83333333 0.66666667]
[0.33333333 0.33333333 0.16666667]
[0.33333333 0.16666667 0.66666667]
[0.33333333 0.83333333 0.33333333]]: ['Ya' 'Ya' 'Tidak' 'Tidak' 'Ya']Variabel Terakhir Non-Numerik Hasil Non-Numerik Klasifikasi x13 Ya x14 Ya x15 Tidak x16 Tidak x17 Ya
hasil klasifikasi Penyelesaian Spreadsheet