Dalam rangka pengembangan Data Science / Big Data, maka Universitas ‘Aisyiyah (UNISA) Yogyakarta membentuk Tim Task Force Pengembangan Data Science Universitas ‘Aisyiyah Yogyakarta pada tanggal 27 Desember 2021. Alhamdulillah-nya, BPTSI telah melaksanakan pelatihan pada https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/, https://pdsi.unisayogya.ac.id/flume-sqoop-dan-kafka-mengumpulkan-dan-memasukkan-big-data/ dan https://pdsi.unisayogya.ac.id/pig-hive-dan-hbase-mengolah-big-data/.
Data Science / Big Data UNISA Yogyakarta Tahap I
Data Science / Big Data Tahap I berfokus pada pengumpulan data melalui scrapping dengan sebuah server yang dapat diatur targetnya oleh analis.
— Data Science / Big Data UNISA Yogyakarta Tahap I

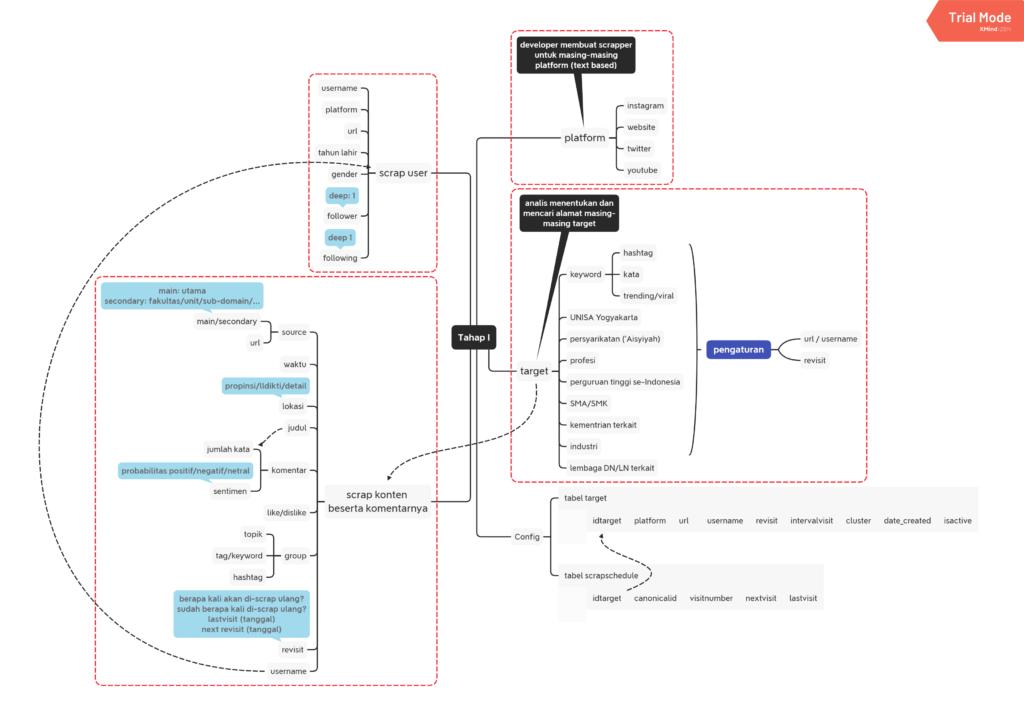
Pengambilan data dimulai dari alamat target yang sudah diberikan oleh analis. Target dapat berupa keyword atau berupa alamat pada platform yang sudah disepakati, antara lain: website, twitter, instagram dan youtube.
Mesin akan mengambil data-data pada status dan komentar-komentar yang ada, sekaligus memisah data ke dalam beberapa komponen, termasuk memberikan penilaian sentimen.
Setiap status akan diatur berapa kali akan dilakukan pengambilan data ulang dalam interval waktu tertentu dalam satuan hari. Hal ini perlu dilakukan karena kemungkinan satu status belum ada komentar pada scrapping pertama, tetapi kemudian beberapa saat kemudian baru muncul komentar.
[Update 25 Maret 2022]
Tahap I adalah scapping text based untuk platform terbuka (API terbuka), seperti website, twitter, instagram, youtube dan lainnya. Tahap II klik di sini.
Programmer/Engineer hanya membuat mesin untuk scrapping tanpa pengaturan yang terintegrasi dengan coding. Pengaturan ada di tabel terpisah yang dibaca oleh mesin. Pengaturan akan diisi oleh Analis, sehingga tidak perlu ‘membongkar’ coding hanya demi menambah target scrap.
Demikian, semoga bermanfaat. [bst]