Big Data secara bahasa adalah data yang besar. Data menjadi besar karena data tumbuh dengan sangat cepat. Hadoop merupakan salah satu teknologi untuk menangani data yang besar tersebut.
Ada banyak teori tentang perspektif Big Data, antara lain adalah 4 V [Volume, Variety, Velocity dan Veracity]. Data besar dalam perspektif skala (banyak/ukuran) data [Volume], berbagai macam bentuk data dan tidak terstruktur [Variety], lalu lintas data (kecepatan pertumbuhan data) [Velocity] dan banyaknya data yang tidak tervalidasi/terstandar/tidak lengkap [Veracity].

Daftar Isi
Apa yang Terjadi pada Data?
Hadoop dapat digunakan untuk menangani Big Data baik dalam bentuk data terstruktur (basis data) maupun tidak terstruktur (file). Hadoop juga melakukan replikasi untuk blok-blok sebagai cadangan apabila terjadi korupsi.
— Administrasi Big Data, Studi Kasus Hadoop

Kondisi sekarang:
- Pertumbuhan data sangat cepat
2021: setiap 1 menit ada 72 jam video diupload di Youtube, 216 ribu pos baru di instagram, 204 juta email dikirim - Peningkatan kapasitas penyimpanan tidak seiring dengan kecepatan akses
2021: hdd 1 TB hanya memiliki kecepatan 100MB/s - Query interaktif terpaksa menjadi query batch
query data besar membutuhkan waktu yang lama - Teknologi dan perangkat keras yang ada tidak mampu menangani data
bottleneck terjadi pada berbagai perangkat keras, misalnya- RDBMS bottleneck pada RAM
- Grid Computing bottleneck pada jaringan
Administrasi Big Data dengan Hadoop
|-Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
https://hadoop.apache.org/
- Open Source berbasis Apache. Berjalan di dalam sistem operasi
- Auto backup dan High Availability
- Menyimpan dan memproses data secara masif
- Menggunakan perangkat keras komoditas
- Didukung oleh banyak perangkat lunak open source
- Digunakan oleh perusahaan teknologi
|-HDFS (Hadoop Distributed File System)
A distributed file system that provides high-throughput access to application data.
https://hadoop.apache.org/
HDFS cocok untuk file berukuran sangat besar, data yang ditulis sekali dengan pembacaan berkali-kali, menggunakan perangkat keras komoditas dan basis data OLAP (online analytical processing).
HDFS tidak cocok untuk akses data dengan latensi rendah, banyak file kecil, modifikasi file secara acak dan basis data OLTP (online transaction processing).
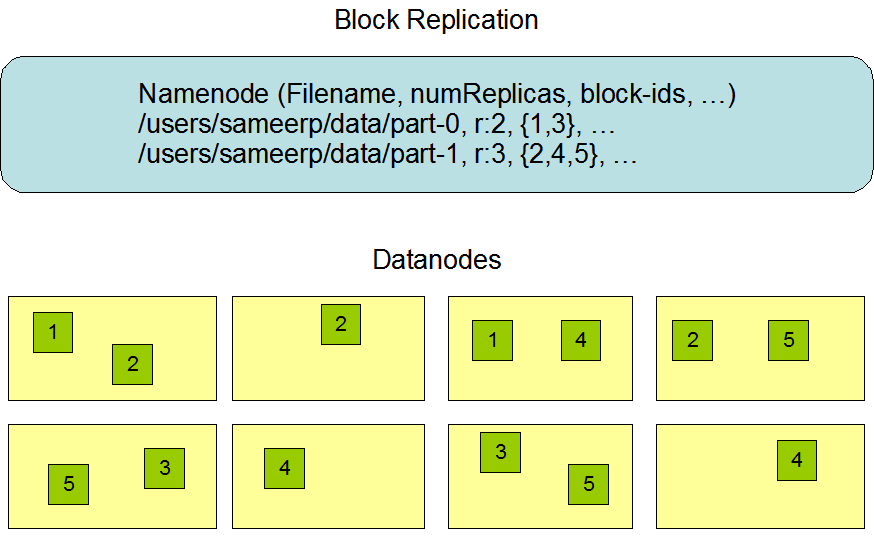
HDFS memiliki konsep blok dengan ukuran blok bawaan adalah 128 Mb. Berkas akan disimpan ke dalam blok-blok tersebut. Misalnya ada file berukuran 200 Mb, maka file tersebut disimpan ke dalam blok berukuran 128 Mb dan 72 Mb.
Berkas (blok-blok) tersebut disimpan ke dalam Datanode dengan konsep replikasi (semacam auto backup). Alamat dimana berkas tersebut disimpan di Datanode berada di Namenode.
|-YARN (Yet Another Resource Negotiator)
A framework for job scheduling and cluster resource management.
https://hadoop.apache.org/
Ide dasar dari YARN adalah membagi fungsi dari manajemen sumber daya dan penjadwalan/pengawasan ke dalam daemon terpisah. Idenya adalah memiliki sebuah ResourceManager (RM) global dan ApplicationMaster (AM) per-aplikasi, baik aplikasi dengan pekerjaan tunggal maupun pekerjaan paralel.
Rencana Tindak Lanjut
Mengimplementasikan Hadoop untuk NAS sebagai media simpan big data web, elearning, dan sebagainya?Gunakan Seaweeds FS (update: 4 Agustus 2021)- Mengimplementasikan Hadoop untuk basis data analisis? Termasuk basis data ODK

Pelatihan hari pertama Big Data Administration with Hadoop (2/8/2021) sebagai bagian dari penggunaan dana hibah PKKM tahun anggaran 2021 dengan mentor Nuzul Fauzan M (https://pdsi.unisayogya.ac.id/unisa-yogyakarta-menerima-bantuan-pemerintah-pkkm-tahun-anggaran-2021/). [bst]
Sumber:
3 replies on “Administrasi Big Data, Studi Kasus Hadoop”
[…] dengan https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/#hdfs adalah menggunakan channel file dan sink […]
[…] pada tanggal 27 Desember 2021. Alhamdulillah-nya, BPTSI telah melaksanakan pelatihan pada https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/, https://pdsi.unisayogya.ac.id/flume-sqoop-dan-kafka-mengumpulkan-dan-memasukkan-big-data/ dan […]
[…] pada tanggal 27 Desember 2021. Alhamdulillah-nya, BPTSI telah melaksanakan pelatihan pada https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/, https://pdsi.unisayogya.ac.id/flume-sqoop-dan-kafka-mengumpulkan-dan-memasukkan-big-data/ dan […]